
SQLite, json et dénormalisation
En parcourant la documentation de SQLite j’ai vu qu’il existait une extension nommée JSON1, qui, vous vous en doutez permet de manipuler du JSON au sein de SQLite.
Dans cet article, nous allons voir comment utiliser cette extension sur une base dénormalisée et l’impact que cela peut avoir sur les performances de lecture.
Le code utilisé est disponible ici
C’est quoi la dénormalisation ?
Si j’en crois cette page. C’est un “Processus consistant à regrouper plusieurs tables liées par des références, en une seule table, en réalisant statiquement les opérations de jointure adéquates.”
Ma version, c’est de dire que l’on va s’autoriser à ne pas utiliser les bonnes pratiques enseignées par nos professeurs #ThugLife. Dans une base dénormalisée on s’éloigne (un peu) du Graal que représente la 3e forme normale et on s’autorise à dupliquer des données notamment en rapatriant les données des tables de jointure dans les “tables normales”. Si ce n’est toujours pas clair, l’exemple qui suit devrait vous aider à mieux comprendre.
Les tables
Plutôt que d’utiliser l’exemple des posts avec des tags, cette fois-ci, on va avoir des bars et des bouteilles de vin. On aura une relation de type many-to-many ou chaque bar peut proposer plusieurs vins et de la même manière, un vin peut être servi dans plusieurs bars.
Nous aurons 4 tables :
- wines : table des vins
- bars_normalized : tables des bars
- bars_wines : table de jointure entre wines et bars_normalized
- bars_denormalized : la table des bars où les vins servis dans ce bar sont stockés en tant que tableau d’identifiant sous le champ wines_ids
CREATE TABLE IF NOT EXISTS wines (
id TEXT PRIMARY KEY,
name TEXT,
country TEXT,
year INTEGER
);
CREATE TABLE IF NOT EXISTS bars_normalized (
id TEXT PRIMARY KEY,
name TEXT
);
CREATE TABLE IF NOT EXISTS bars_wines (
bar_id TEXT,
wine_id TEXT
);
CREATE TABLE IF NOT EXISTS bars_denormalized (
id TEXT PRIMARY KEY,
name TEXT,
country TEXT,
wines_ids JSON /* contiendra: ["wine-uuid-1","wine-uuid-234"...] */
);
Présentation de JSON1
Regardons comment effectuer les opérations usuelles sur la table bar_denormalized.
Insertion
INSERT INTO bars_denormalized (id, name, wines_ids)
VALUES (
'random-uuid',
'La taverne',
/* La méthode json() permet de vérifier que le JSON fourni est valide
et aussi de supprimer les espaces inutiles */
json('["wine-uuid-1", "wine-uuid-45", "wine-uuid-423"]')
);
Lecture
SELECT DISTINCT bars_denormalized.id, bars_denormalized.name
/* 1 - La méthode json_each() permet de sélectionner le champ
sur lequel nous allons itérer */
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
/* 2 - Une fois qu'un champ a été sélctionné avec json_each(),
on peut utiliser json_each.value pour récupérer la valeur
de chacun des éléments du tableau */
WHERE json_each.value = 'wine-uuid-1';
La requête ci-dessus va, pour chaque bar, itérer sur le tableau wines_ids. Et pour chaque élément du tableau, il va vérifier s’il est égal à l’identifiant wine-uuid-1.
Finalement, cette requête renvoie tous les bars proposant le vin ayant pour identifiant wine-uuid-1.
Si nous avions eu un objet nous aurions pu utiliser la méthode json_extract. Si nous avions un tableau d’objets, la méthode json_tree.
Mise à jour et suppression
Ces deux opérations vont fonctionner de manière similaire. Dans un cas, on va venir ajouter un nouvel identifiant dans le tableau wines_ids et dans l’autre cas, on viendra en supprimer un.
UPDATE bars_denormalized
SET wines_ids = (
/* 2 - On insert la valeur à l'indice donné, à la fin du tableau */
SELECT json_insert(
bars_denormalized.wines_ids,
/* 1 - On récupère la longueur du tableau actuel, qui sera l'indice
du nouvel élément */
'$[' || json_array_length(bars_denormalized.wines_ids) || ']',
'wine-uuid-297'
)
)
WHERE id = 'bar-uuid-3';
La fonction json_insert prend trois paramètres :
- le champ dans lequel on va insérer une valeur
- l’indice auquel on va insérer cette valeur
- la valeur
/* 3 - On met à jour le champ wines_ids avec le nouveau tableau */
UPDATE bars_denormalized
SET wines_ids = (
/* 2 - On retourne un tableau sans l'élément dont l'indice a été
retourné par la sous-requête en 1 */
SELECT json_remove(bars_denormalized.wines_ids,
'$[' || (
/* 1 - On cherche l'indice de l'élément à supprimer */
SELECT json_each.key
FROM json_each(bars_denormalized.wines_ids)
WHERE json_each.value = 'wine-uuid-297'
) || ']'
)
WHERE id = 'bar-uuid-3';
La fonction json_remove prend deux paramètres :
- le champ dans lequel on va retirer une valeur
- l’indice de la valeur que l’on souhaite supprimer
Les requêtes
Pour tester les performances des deux schémas de bases de données, les requêtes auront les buts suivants :
- obtenir les noms des bars proposant des vins datant des années supérieures à 2018
- obtenir les noms des vins portugais qui sont servis dans des bars du royaume-uni
Avec ces deux requêtes, on pourra voir comment faire des requêtes “dans les deux sens”.
Pour la version normalisée, on va effectuer une jointure entre les tables wines, bars_normalized et bars_wines. On viendra ensuite appliquer les filtres selon nos besoins.
SELECT DISTINCT bars_normalized.id, bars_normalized.name
FROM bars_normalized
LEFT OUTER JOIN bars_wines
ON bars_normalized.id = bars_wines.bar_id
LEFT OUTER JOIN wines
ON wines.id = bars_wines.wine_id
WHERE year > 2018;
SELECT DISTINCT wines.id, wines.name
FROM wines
LEFT OUTER JOIN bars_wines
ON wines.id = bars_wines.wine_id
LEFT OUTER JOIN bars_normalized
ON bars_normalized.id = bars_wines.bar_id
WHERE bars_normalized.country = 'United Kingdom'
AND wines.country = 'Portugal';
Concernant la version dénormalisée on va utiliser les méthodes fournies par l’extension JSON1, json_each dans notre cas.
SELECT DISTINCT bars_denormalized.id, name
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
WHERE json_each.value IN (
SELECT id
FROM wines
WHERE year > 2018
);
SELECT DISTINCT wines.id, wines.name
FROM wines
WHERE id IN (
SELECT DISTINCT json_each.value AS id
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
WHERE bars_denormalized.country = 'United Kingdom'
) AND wines.country = 'Portugal';
Petit aparté concernant la requête ci-dessus, ou plutôt la sous-requête. Si on s’en tient au sens de lecture, il peut paraitre bizarre que j’utilise json_each.value dans le SELECT alors que je vais charger ces données dans la clause FROM qui est la ligne suivante. Et justement, il faut comprendre comment les bases relationnelles interprètent les requêtes, elles sont éxecutées comme présentée dans le schema suivant.
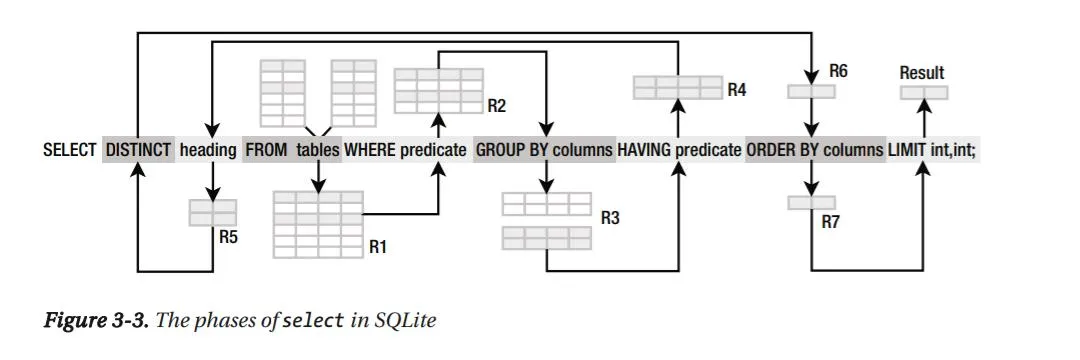
Ainsi, même si cela ne semble pas naturel au vu du sens de lecture, c’est en revanche tout à fait valide d’un point de vue technique.
Résultats
Lectures
J’ai effectué les tests en faisant varier différents paramètres. Sur chacune des requêtes ci-dessous, les nombres entre parenthèses représentent : (nombre de bars, nombre de vins, nombre de vins par bar).
Les résultats sont des médianes d’une série de 5 requêtes.
| Normalisée | Dénormalisée | |
|---|---|---|
| Requête 1 (500, 1000, 100) | 874ms | 74ms |
| Requête 1 (5000, 10000, 100) | 9143ms | 569ms |
| Requête 1 (500, 1000, 500) | 4212ms | 197ms |
| Requête 2 (500, 1000, 100) | 726ms | 16ms |
| Requête 2 (5000, 10000, 100) | 8648ms | 83ms |
| Requête 2 (500, 1000, 500) | 4132ms | 27ms |
Cela saute aux yeux, la version dénormalisée est plus rapide que la version normalisée et de loin lorsque l’on augmente la quantité de données. Les jointures sont des opérations très voraces. Pour les bases normalisées la durée semble plus ou moins corrélée à la taille de la table de jointure. Prenons comme exemple la requête 1 :
- 50000 entrées → 874ms
- 500000 entrées → 9143ms (x10 par rapport à ci-dessus)
- 250000 entrées → 4212ms (÷2 par rapport à ci-dessus)
Les valeurs sont similaires pour la requête 2. Ainsi, la durée devrait évoluer linéairement par rapport à la quantité de données. Ce n’est pas un phénomène que l’on peut observer avec la forme dénormalisée, qui semble, mieux supporter l’augmentation de la quantité de données.
De plus, on peut observer quelque chose d’intéressant sur la partie dénormalisée. La requête 2 est plus performante que la requête 1. Autrement dit, requêter sur la table qui ne porte pas le tableau d’identifiant est plus performant. Ce qui veut dire que l’on a intérêt à faire porter le tableau d’identifiants à la table sur laquelle on ne veut pas faire de traitement complexe. Dans mon exemple si j’ai besoin de charger plus souvent les données relatives au bar, j’aurais tout intérêt à faire porter un bars_ids à ma table wines, plutôt que de conserver le wines_ids.
Taille des tables
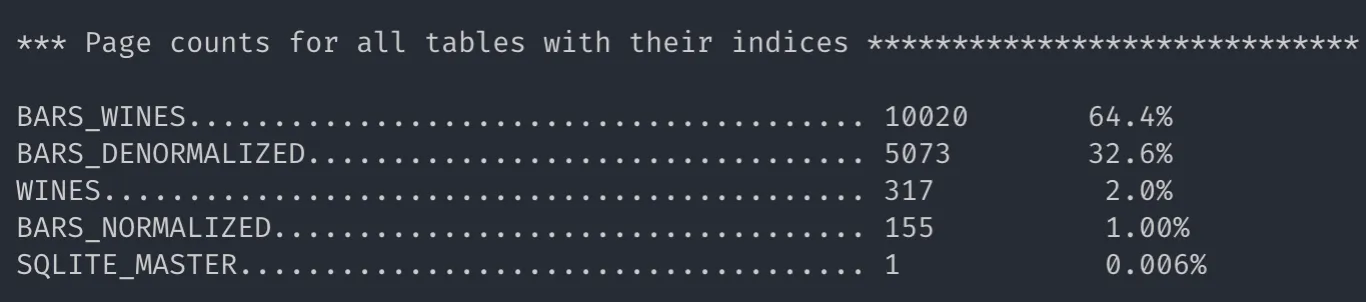
Ces statistiques sont fournies par l’outil sqlite3_analyzer. La version table des bars en version dénormalisée est environ deux fois plus légère que la version normalisée comprenant les tables bars_normalized et bars_wines. La dénormalisation en plus d’un gain de performances en lecture permet d’alléger la taille totale de notre base ! Qui l’eût cru ?
Conclusion
La dénormalisation est assurément une bonne solution pour gagner en performance de lecture. Cependant, il faut être vigilant sur les opérations d’écritures. Notamment, lors d’une suppression, on ne pourra pas profiter des suppressions en cascades offertes par les bases relationnelles.
À travers cet article, je voulais aussi montrer que la dénormalisation n’est pas un concept exclusif aux bases NoSQL. D’après les recherches rapides que j’ai pu effectuer, MySQL/MariaDB et PostreSQL supportent aussi la manipulation de JSON. Je ne jette pas le discredit sur les bases NoSQL, elles peuvent être plus adaptées que les bases relationnelles dans certains cas, Redis et ElasticSearch sont de parfaits exemples. Mais il n’est pas nécessaire de mettre de côté les solutions éprouvées.
Merci de m’avoir lu.
Liens
- https://www.sqlitetutorial.net
- https://stackoverflow.com/questions/49451777/sqlite-append-a-new-element-to-an-existing-array
Le mot de la fin
Merci à Jérémy Merle et Marvin Frachet pour la relecture.
Quand à Val, l’autre Jérem et Clapette 🖕😉