
Déploiement continu avec CircleCI - Partie 1
Je vous propose de mettre en place un déploiement continu en utilisant Condorcet, un de mes projets, comme exemple. Le but est de présenter les différents concepts inhérents à CircleCI au travers d’un cas concret. Dans la première partie on mettra en place une solution fonctionnelle que l’on optimisera en seconde partie.
L’application
Cette application est faite avec Vue.js et utilise Firebase pour la gestion utilisateurs et le stockage des données. Nous allons aussi utiliser Firebase pour héberger l’application.
Les scripts du package.json :
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
"test:unit": "vue-cli-service test:unit"
}
servelance le serveur de développementbuildconstruit une application statique pour la productionlintvérifie que le code respecte les règles définies par ESLinttest:unitlance les tests unitaires
Parmi ces scripts j’aimerais que build, lint et test:unit soient lancés à chaque fois que je cherche à intégrer du code dans master. Car master doit toujours être stable 🥐.
Pour éviter de le faire manuellement je vais utiliser CircleCI. Cet outil va lancer les scripts à chaque fois que je push un commit sur Github.
Ajouter CircleCI à son projet
Pour ajouter CircleCI à un dépôt il faut se rendre dans la Marketplace de Github :
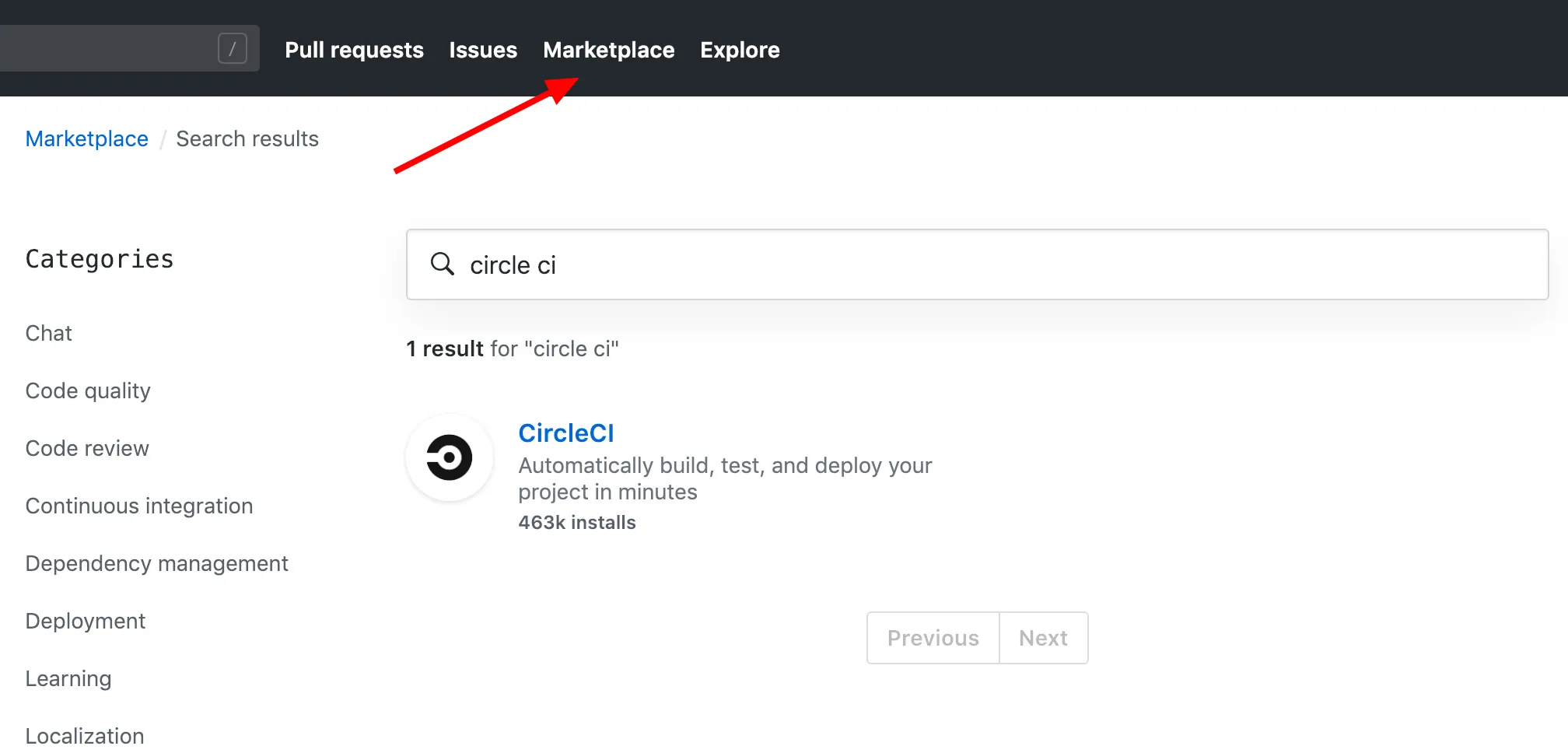
Pour un projet open source il faut sélectionner l’option “Free”, à moins que vous ne souhaitiez sortir le chequos :
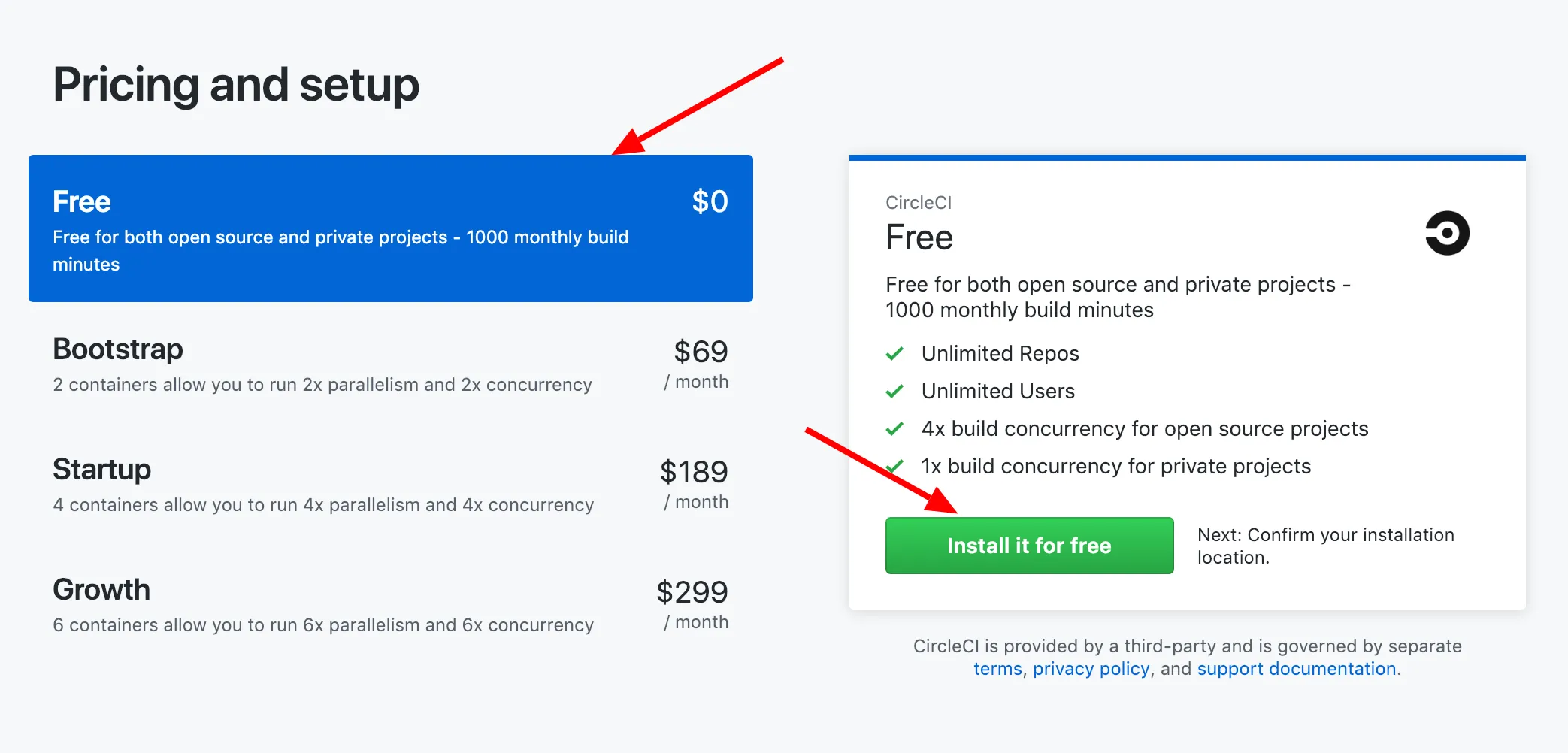
Après avoir validé l’installation de CircleCI on peut ajouter un projet Github à CricleCI :
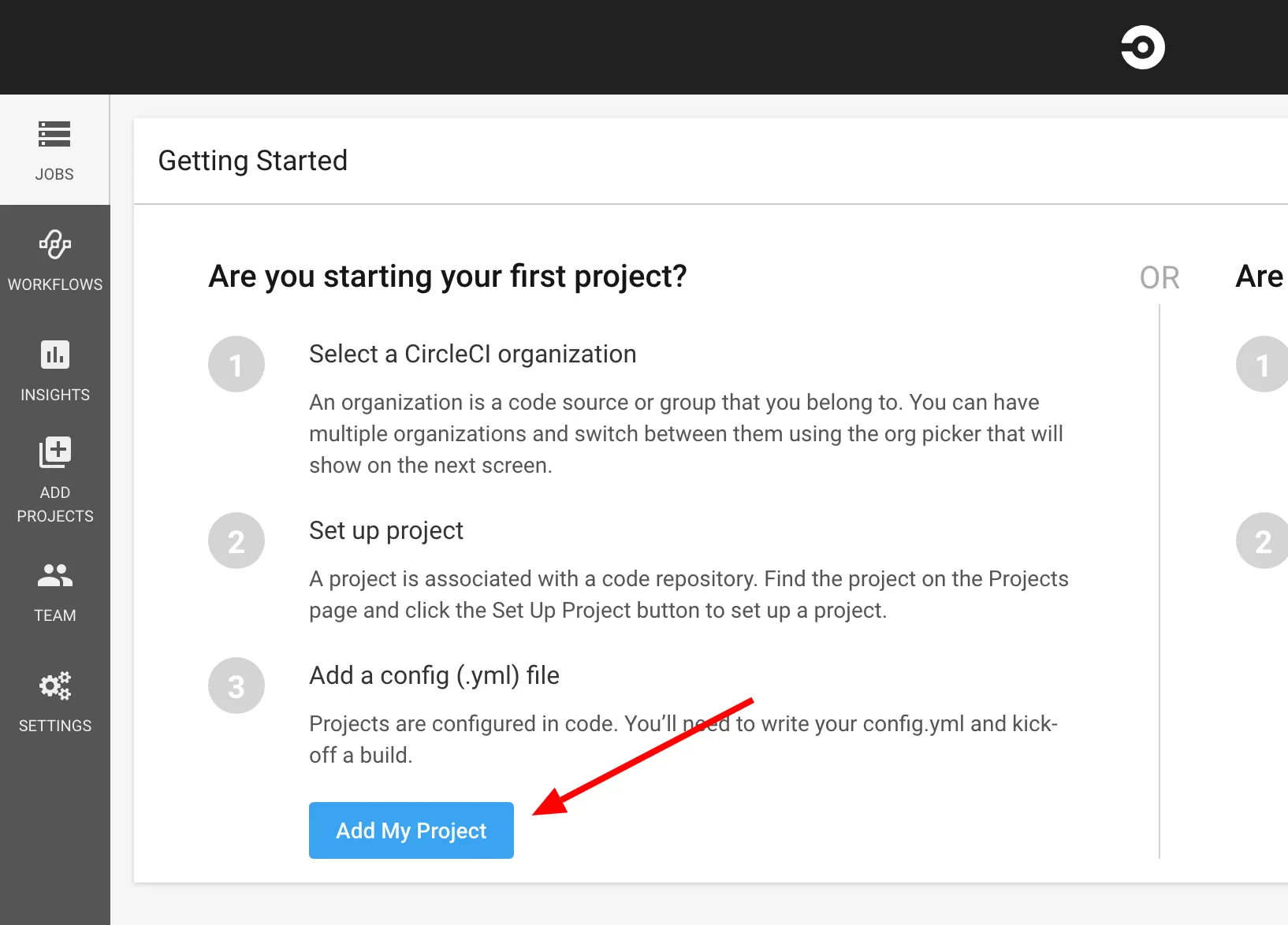
Nous arrivons sur la page des projets :
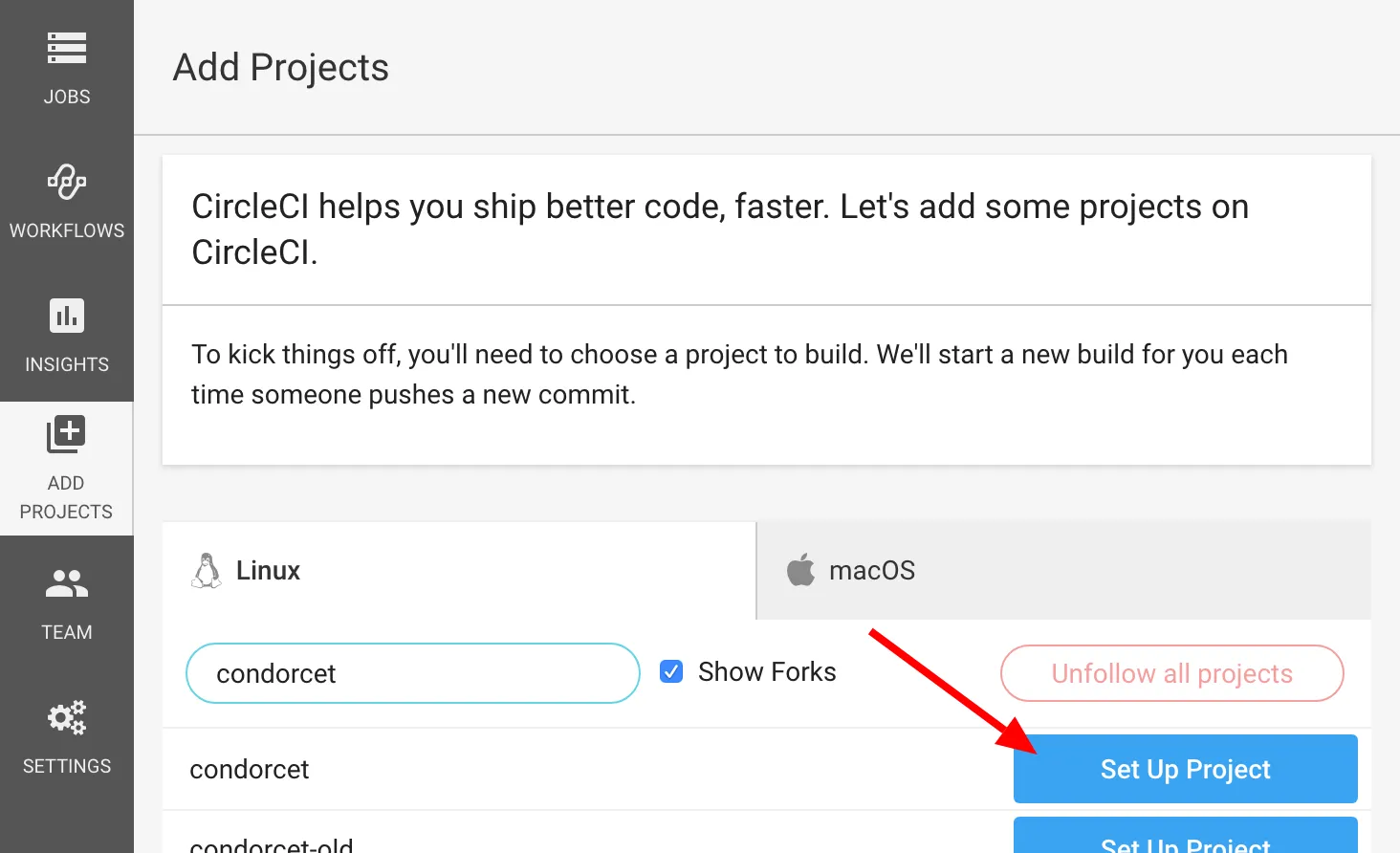
Sur cette page il est possible de sélectionner l’environnement dans lequel nous allons effectuer nos tests :
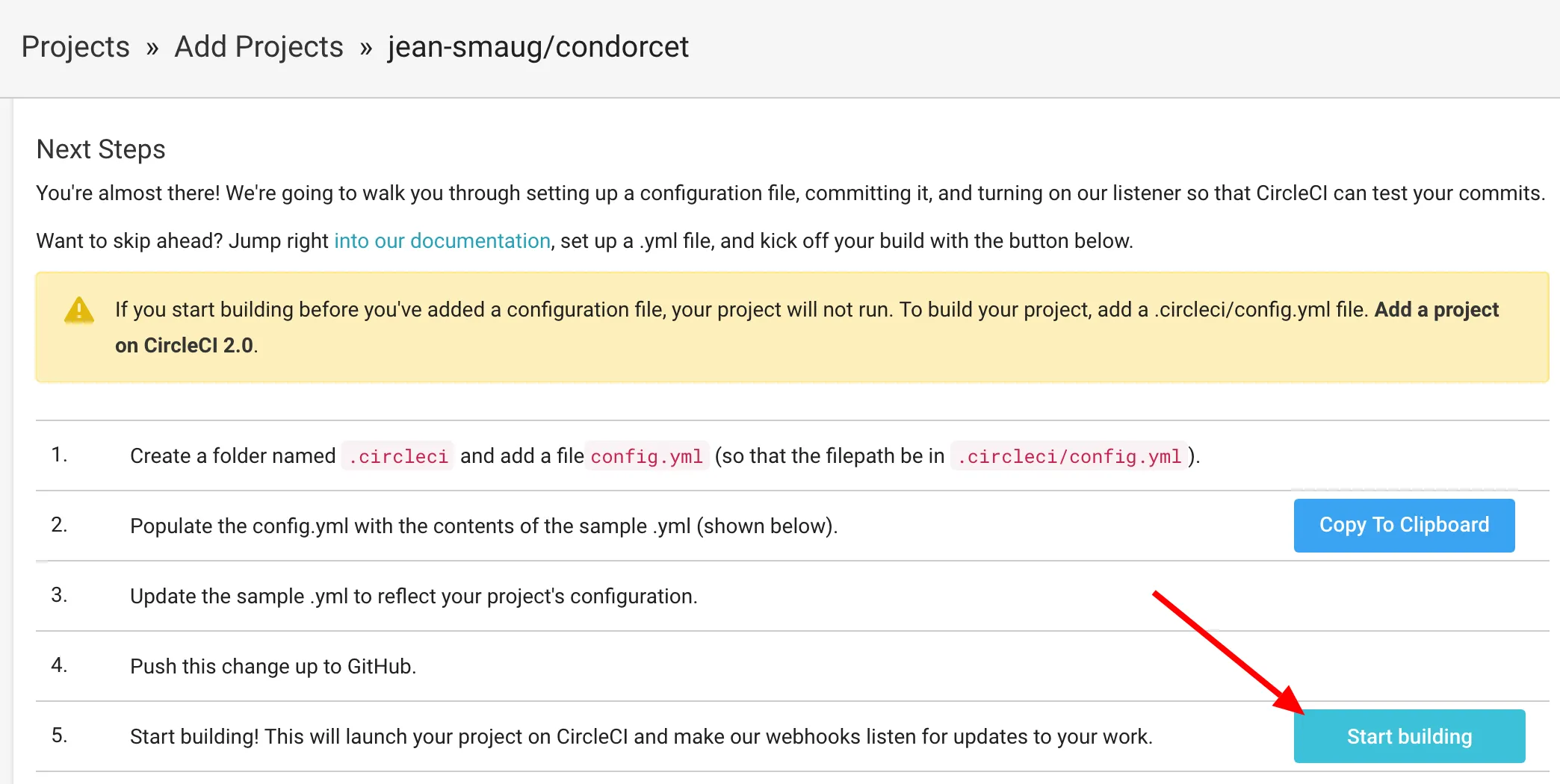
Première étape validée, on passe à la configuration.
Définition des jobs
Pour CircleCI un job représente une succession d’instructions. Pour un projet open source nous pouvons avoir 4 jobs maximum s’exécutant en parallèle. Concrètement, chacun des trois scripts aura un job qui lui sera dédié et nous pourrons ainsi lancer 3 jobs en parallèle, un pour chaque script. Ainsi chacun des scripts sera lancé dans un environnement isolé n’impactant pas les autres.
L’exemple ci-dessous montre à quoi ressemble la définition d’un job :
build:
docker:
- image: circleci/node:11.10.1
steps:
- checkout
- run: yarn install
- run: yarn build
build: le nom du jobdocker: l’environnement dans lequel sera exécuté notre job, ici Dockerimage: l’image que doit utiliser Docker, ici Node.js
steps: liste de nos instructionscheckoutpermet de se placer dans le dossier projet créé par CircleCIrun: yarn installinstalle les dépendancesrun: yarn buildconstruit une application statique destinée à la production
NB : les commandes shell doivent être précédées d’un run:
On répète l’opération pour chacun des scripts et on obtient la configuration suivante pour les trois jobs :
version: 2.1
jobs:
build:
docker:
- image: circleci/node:11.10.1
steps:
- checkout
- run: yarn install
- run: yarn build
lint:
docker:
- image: circleci/node:11.10.1
steps:
- checkout
- run: yarn install
- run: yarn lint
test:
docker:
- image: circleci/node:11.10.1
steps:
- checkout
- run: yarn install
- run: yarn test:unit
workflows:
version: 2
integration:
jobs:
- build
- lint
- test
version: la version du fichier de configuration, actuellement 2.1jobs: la liste de nos différents jobsworkflows: un scénario d’exécution des différents jobsversion: version du workflow, actuellement 2integration: le nom du workflowjobs: la liste des jobs à executer. Ici nos trois jobs seront exécutés en parallèle
Désormais lorsque l’on pushera du code sur Github on pourra voir l’état de nos tests sur CircleCI :
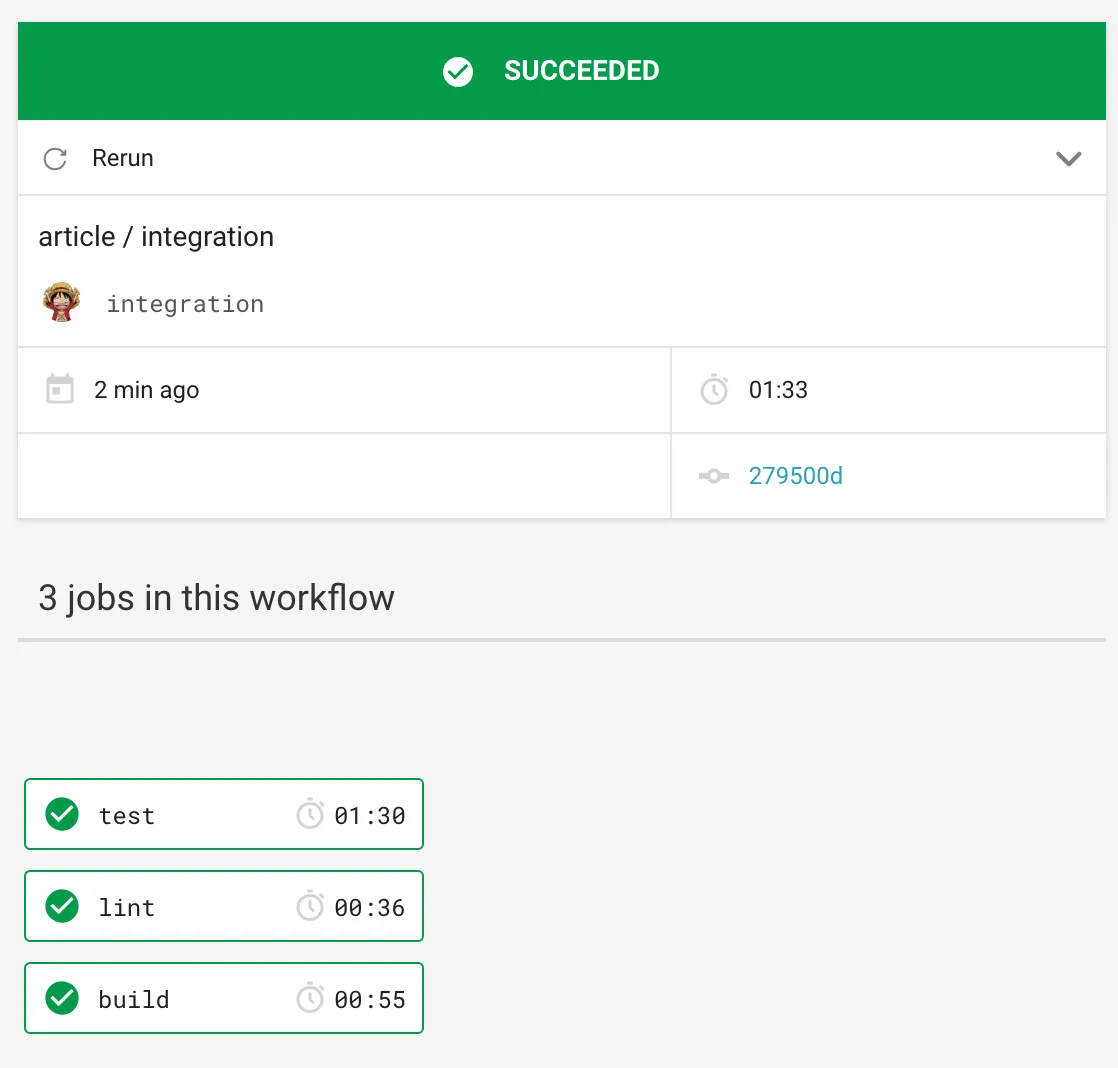
Cela est aussi visible directement depuis une Pull Request sur Github :
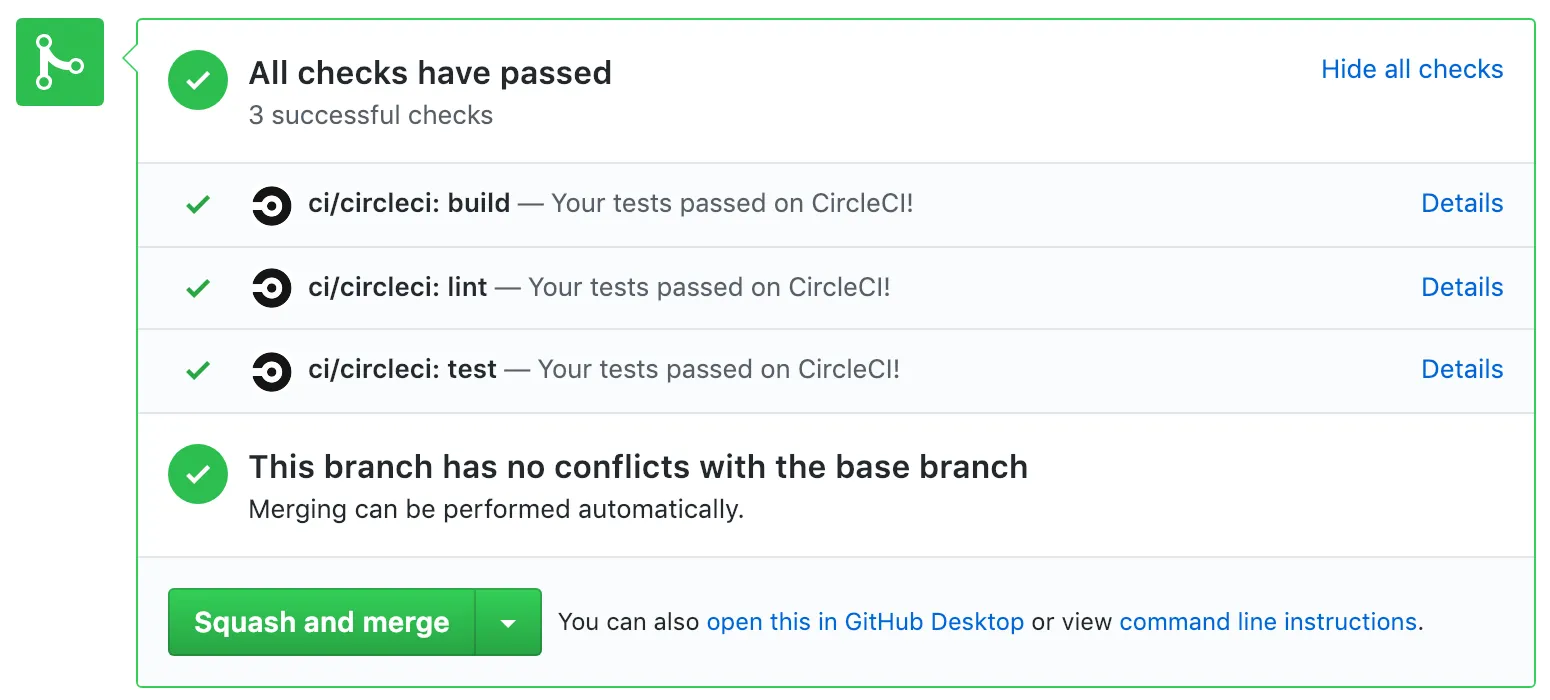
Déploiement
Maintenant que l’intégration fonctionne il serait génial de déployer automatiquement notre code lorsqu’un nouveau commit apparait sur la branche master. Que ce soit via une pull request ou un push (force 🙄)
Je fais un petit aparté sur Firebase mais qui sait, peut-être que ça en intéressera certains 🤷♂️.
Pour déployer des fichiers statiques sur le service hosting de Firebase via une CI il faut :
- installer les outils Firbase en local avec un
yarn global add firebase-tools. - lancer un
firebase login:ciafin d’obtenir un token
Ce token sera utilisé pour autoriser la CI à déployer sur Firebase.
Pour ajouter un token il faut aller dans les paramètres :
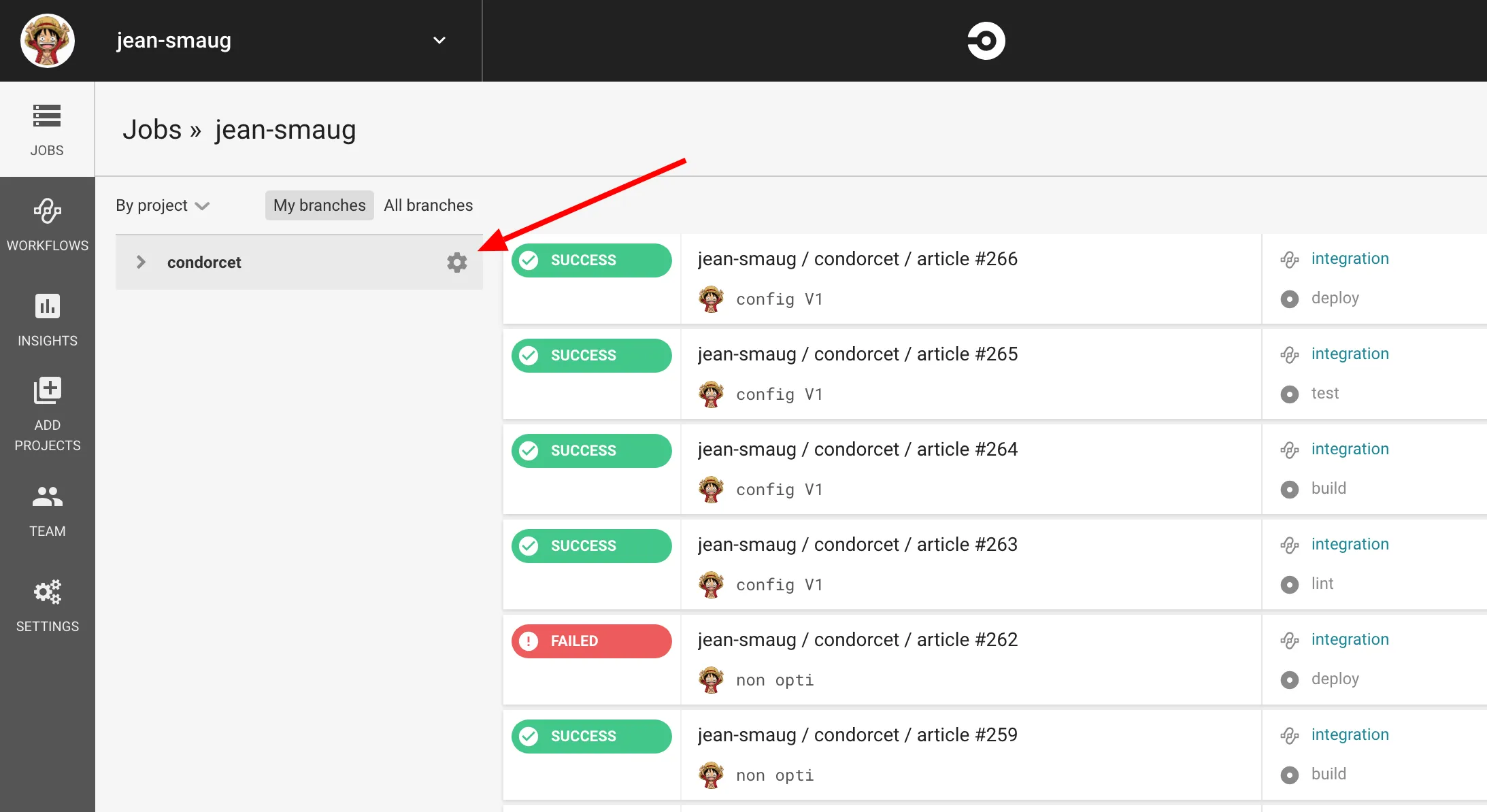
Et ajouter le token en tant que variable d’environnement, ici elle sera appelée FIREBASE_TOKEN :
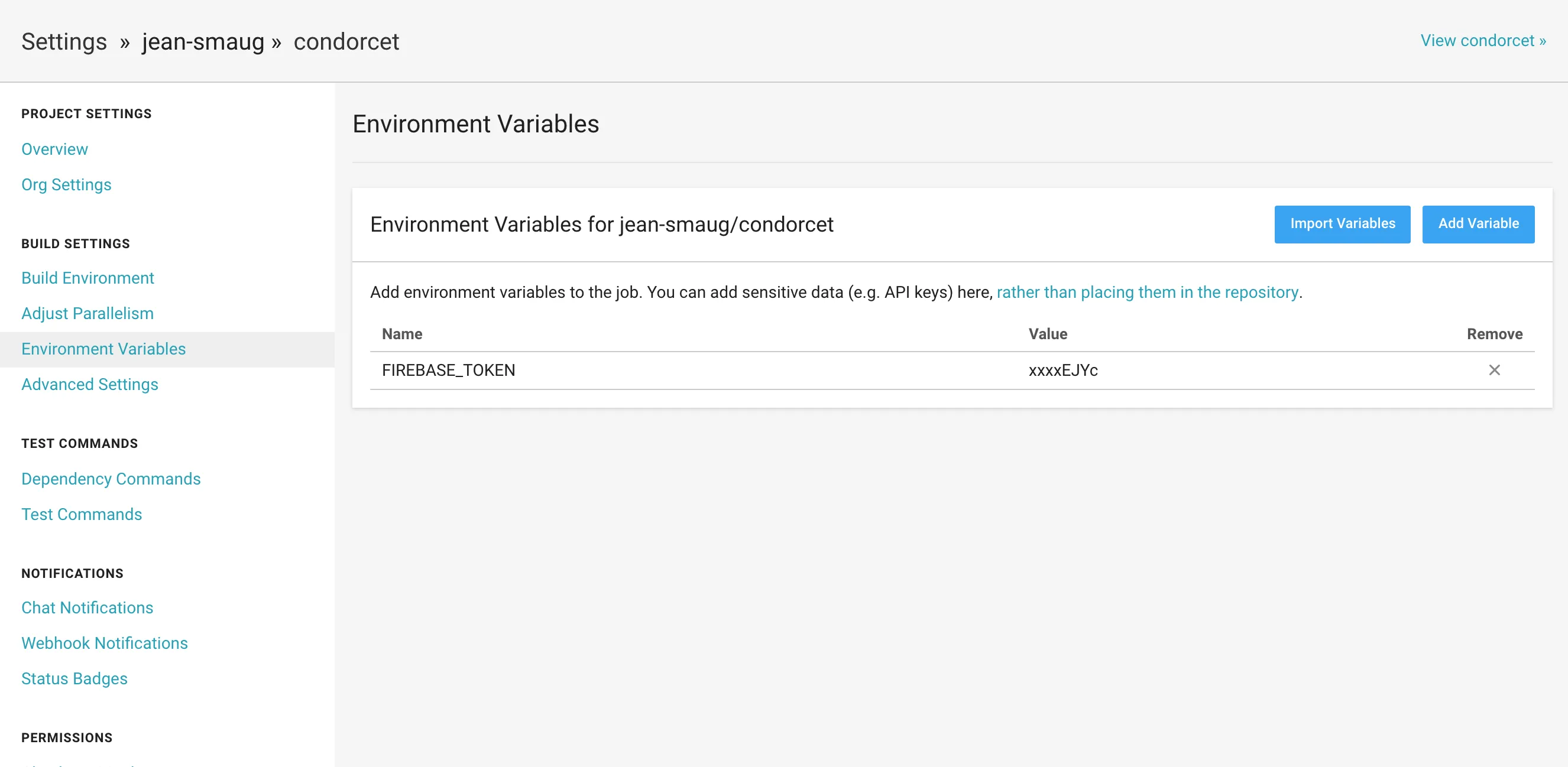
On pourra alors réutiliser la variable d’environnement dans notre fichier de configuration :
version: 2
jobs:
## les autres jobs...
deploy:
docker:
- image: circleci/node:11.10.1
steps:
- checkout
- run: yarn install
- run: yarn build
- run: yarn firebase deploy --token "$FIREBASE_TOKEN" --only hosting
workflows:
version: 2
integration:
jobs:
- build
- lint
- test
- deploy:
requires:
- build
- lint
- test
filters:
branches:
only: master
Dans le nouveau job : deploy, on utilise la variable $FIREBASE_TOKEN que l’on vient de créer.
Ensuite il suffit d’ajouter ce job à notre workflow en lui ajoutant des options :
requires: les jobs qui doivent être complétés avant d’exécuter ce jobfilters: permet de préciser pour quelles branches, quels tags… ce job doit s’exécuter. Dans notre cas, uniquement sur la branchemaster
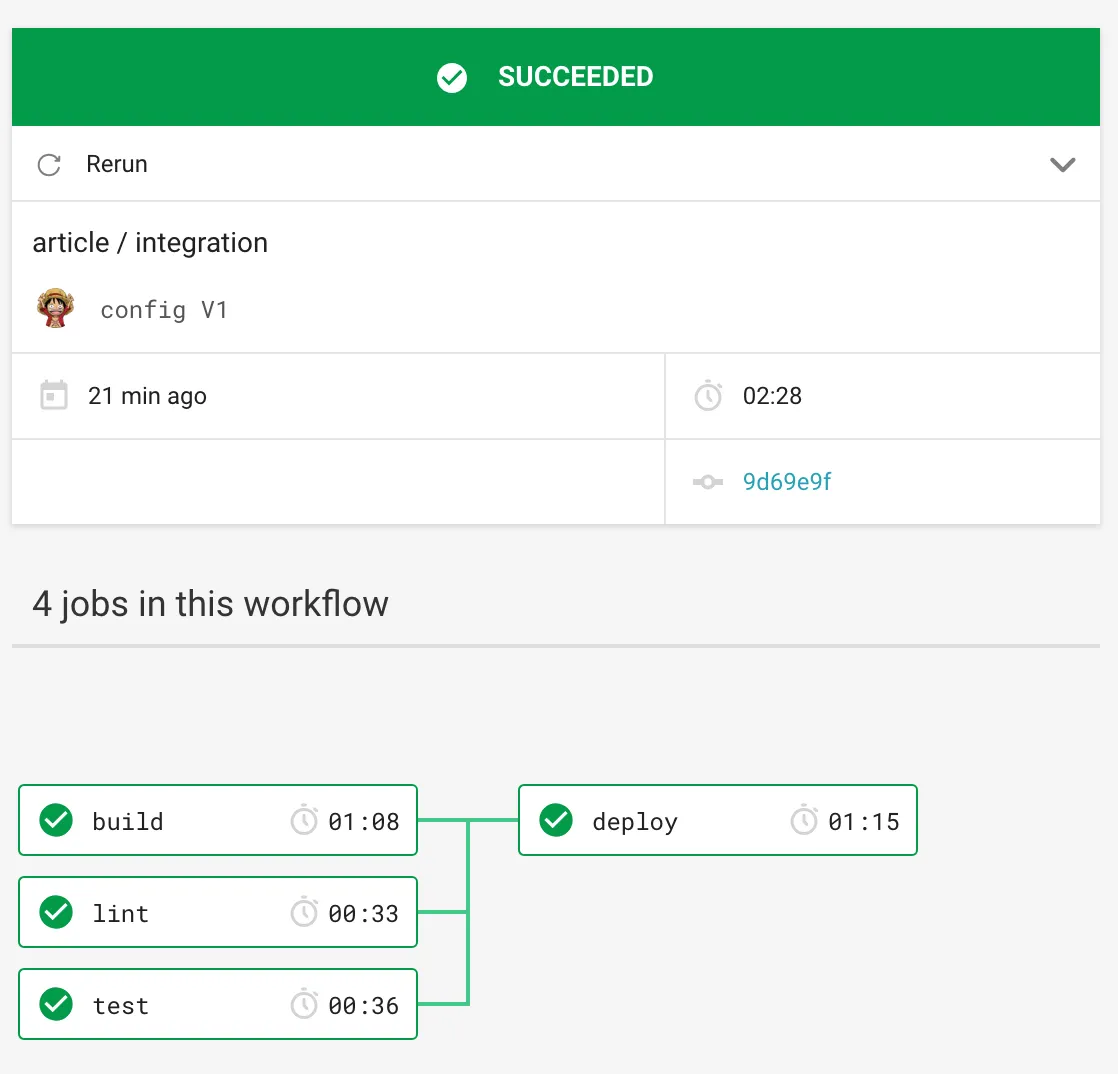
Résumé
Les jobs sont une suite d’instructions.
Un workflow définit la manière dont les différents jobs seront exécutés. On peut exécuter nos jobs en parallèle, en séquentiel, uniquement sur certaines branches…
On peut ajouter des variables d’environnements contenant des informations confidentielles via l’UI et utiliser ces variables dans notre configuration en les précédant d’un $.
Prochaine étape
Dans l’absolu notre configuration fonctionne, mais il est possible de faire mieux. Dans l’article suivant on va améliorer la configuration pour gagner un temps de malade. 😎